
当你要求一个大型语言模型总结策略或编写代码时,你可能会假设它会安全运行。但是,当有人试图欺骗它泄露数据或生成有害内容时,会发生什么?这个问题正在推动人工智能护栏研究浪潮,一个名为OpenGuardrails的新开源项目正在朝着这个方向迈出大胆的一步。

该项目由OpenGuardrails.com的Thomas Wang和香港理工大学的Haowen Li创建,为检测大型语言模型中的不安全、被操纵或侵犯隐私的内容提供了一种统一的方法。它侧重于许多公司一旦开始大规模使用人工智能就会遇到的问题:如何在不每次都重写系统的情况下使安全控制适应不同的环境。
人工智能安全的灵活方法
OpenGuardrails的核心是所谓的可配置策略适应。组织可以针对什么被视为不安全,而不是固定的安全类别来定义自己的规则,并调整模型对这些风险的敏感性。
这种灵活性可能会对生产产生很大影响。金融公司可能专注于检测数据泄露,而医疗保健提供者可能会收紧有关医疗错误信息的政策。配置可以在运行时更新,允许系统随着需求或法规的变化而适应。
这种设计将适度变成了一个活的过程,而不是一次性设置。它还旨在减少对不确定案例的手动审查,因为管理员可以通过单个参数调整系统应该有多谨慎。
OpenGuardrails首席执行官Thomas Wang表示,该团队已经看到了可配置的灵敏度阈值在该领域是多么有价值。他说:“我们已经运行OpenGuardrails的现实世界企业部署一年多了,事实证明,可配置的灵敏度阈值对于适应不同业务领域的多样化风险承受能力至关重要。”
他解释说,每次新的部署都从“灰色推出”期开始。“在每个新的用例中,企业从一周的灰色推出阶段开始,使用默认的敏感性设置,并且仅使用自残或暴力等高风险类别。在这个阶段,系统收集校准数据和操作反馈,然后部门通过仪表板微调其阈值,”王说。
他补充说,这个过程在非常不同的环境中显示出一致的结果。“我们的一个客户是一家提供人工智能驱动的青年心理健康咨询的公司,要求对自我伤害检测非常敏感,即使在多轮对话中也是如此。另一家企业运营一个用于投诉处理客户支持的人工智能系统,它使用更低的亵渎敏感性,只标记最严重的侮辱以触发升级。”
InfluxData的首席信息安全官Peter Albert表示,采用这种工具应该需要对长期勤奋的承诺。“一旦你决定采用像OpenGuardrails这样的工具,就要求任何商业产品都要进行同样的严格验证。建立定期的依赖性检查,社区监测新的漏洞,以及定期的内部渗透测试。将此与外部验证相结合,并要求至少每年进行一次独立审计,”他说。
Albert的观点强调了CISO越来越期望开源工具符合与专有软件相同的安全和治理标准。OpenGuardrails的透明度使这成为可能,但它也要求组织在监控和验证方面保持积极作用。
一个模型,许多防御
以前的安全系统通常依赖多个模型,每个模型都处理不同类型的问题,如快速注入或代码生成滥用。OpenGuardrails简化了该结构。它使用一个大型语言模型来处理安全检测和操纵防御。
这种方法有助于系统理解微妙的意图和上下文,而不是仅仅依赖禁止的单词过滤器。它还简化了部署,因为组织不需要协调单独的分类器或服务。该模型以量化形式运行,使延迟足够低,以便实时使用。
该团队构建了该系统,可以作为网关或API进行部署,使企业能够控制如何集成它。该平台可以在组织的基础设施内私下运行,符合对数据隐私和监管合规性日益增长的需求。
王表示,该公司已经在扩大其工作范围,以抵御新型攻击。他解释说:“我们拥有一支专门的安全研究团队,该团队跟踪新发布的越狱技术,并通过内部红队和对抗实验发现新的0日攻击。”“与此同时,我们的OpenGuardrails SaaS平台从生产环境中遇到基于提示的新型攻击的用户那里提供了持续的现实世界威胁情报。”
多语言设计
OpenGuardrails的一个突出特点是其广泛的语言覆盖范围。它支持119种语言和方言,这使得它与在不同地区运营的公司相关。很少有开源审核工具能够管理这种规模。
为了加强该领域的研究,该团队还发布了一个数据集,该数据集合并了几个中国安全数据集的翻译和对齐版本,并在Apache 2.0许可证下免费提供。该版本为未来多语言安全工作奠定了基础。
强劲的成果,公开发布
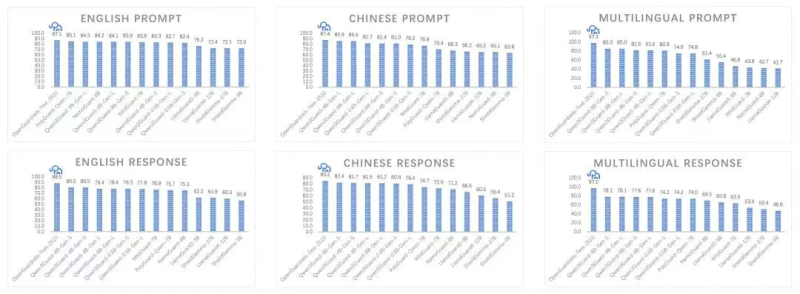
该系统在英语、中文和多语言基准测试中表现良好。在提示和响应分类测试中,它在准确性和响应一致性方面一直高于以前的防护模型。
但表演只是故事的一部分。通过将模型和平台作为开源发布,作者使其他人能够研究、审计和构建他们的工作。这种开放性可以帮助加快安全研究的进展,同时为企业提供一种测试和调整模型以满足自身需求的方法。
Albert的建议强调,开放应该与问责制齐头并进。他对审计和内部测试的强调与项目的开放设计一致,鼓励组织在不假设它们是万无一失的情况下整合护栏。
考虑到生产而建造
OpenGuardrails是为企业使用而构建的。它可以处理高流量,同时保持稳定的响应时间,其模块化组件可以适应现有的人工智能管道。该模型产生概率置信分数,允许管理员设置数字阈值,以调整节制的严格程度。
这种调整灵敏度的能力为对误报和阴性提供了更多的控制,帮助组织将适度严格性与其风险容忍度和工作流程保持一致。
Hexnode首席执行官Apu Pavithran表示,虽然护栏加强了人工智能的监督,但它们也会带来运营压力。“警时疲劳会很快成为一个问题。大多数管理员已经分散了,添加新的检测工具可以大大增加他们的工作量,”他说。
Pavithran补充说,端点层面的主动控制可以减轻这一负担。“出于这个原因,防止风险行为(以及违反人工智能政策)的解决方案将这个问题扼杀在萌芽状态。端点级控制是做到这一点的好方法,因为统一端点管理可以将未经授权的应用程序列入黑名单,防止特定文件上传到外部服务,并在请求到达护栏之前强制执行设备策略,”他解释道。
他说,最好的结果来自于技术和人为因素的结合。“护栏有助于设定人工智能标准,但与更严格的端点控制、用户培训和更好的监督配合得最好,仅举几例。当结合在一起时,文化培训和技术控制有助于比任何单一解决方案本身所能提供的更强大的防御。”
工作还有待完成
尽管它表现强劲,但作者承认了局限性。该模型仍然容易受到旨在绕过其过滤器的有针对性的对抗性攻击。公平和文化偏见也仍然是挑战,因为不同地区对不安全内容的定义不同。该团队计划探索区域微调和定制培训,以处理当地要求。
他们还指出,更强大的防御可能来自工程改进和与外部研究人员的合作。
OpenGuardrails在GitHub上可用。





















暂无评论内容